AI Retrieval Intelligence Engine – Deterministic Citation Likelihood & Structural Extractability Modeling Platform_
Section-aware retrieval scoring system designed to evaluate structural extractability, informational density, topic reinforcement strength, and citation readiness for AI-powered search systems using deterministic backend modeling.
Project Overview
AI-powered search systems retrieve and cite content differently from traditional ranking-based search engines.
Large language models and AI-native interfaces prioritize:
- Structured segmentation
- Informational density
- Topic reinforcement consistency
- Citation-safe content blocks
- Extractable, self-contained sections
Traditional SEO tools measure:
- Keyword rankings
- Visibility indexes
- Backlinks
- Traffic fluctuations
They do not model:
- Structural extractability
- Section-level retrievability
- Topic reinforcement strength
- Informational density by segment
- Citation readiness likelihood
They do not approximate how AI retrieval systems evaluate content blocks.
The AI Retrieval Intelligence Engine was built to solve that gap.
It ingests a live URL, parses structural segmentation, performs lemma-based topic modeling, computes section-level informational density, evaluates entity clarity, and generates deterministic citation readiness scores all through server-side modeling.
This is not a keyword tool. It is a retrieval intelligence engine.
What It Does
The system ingests:
- Any public URL
- Full HTML structure
- Heading hierarchy
- Visible content sections
Then computes:
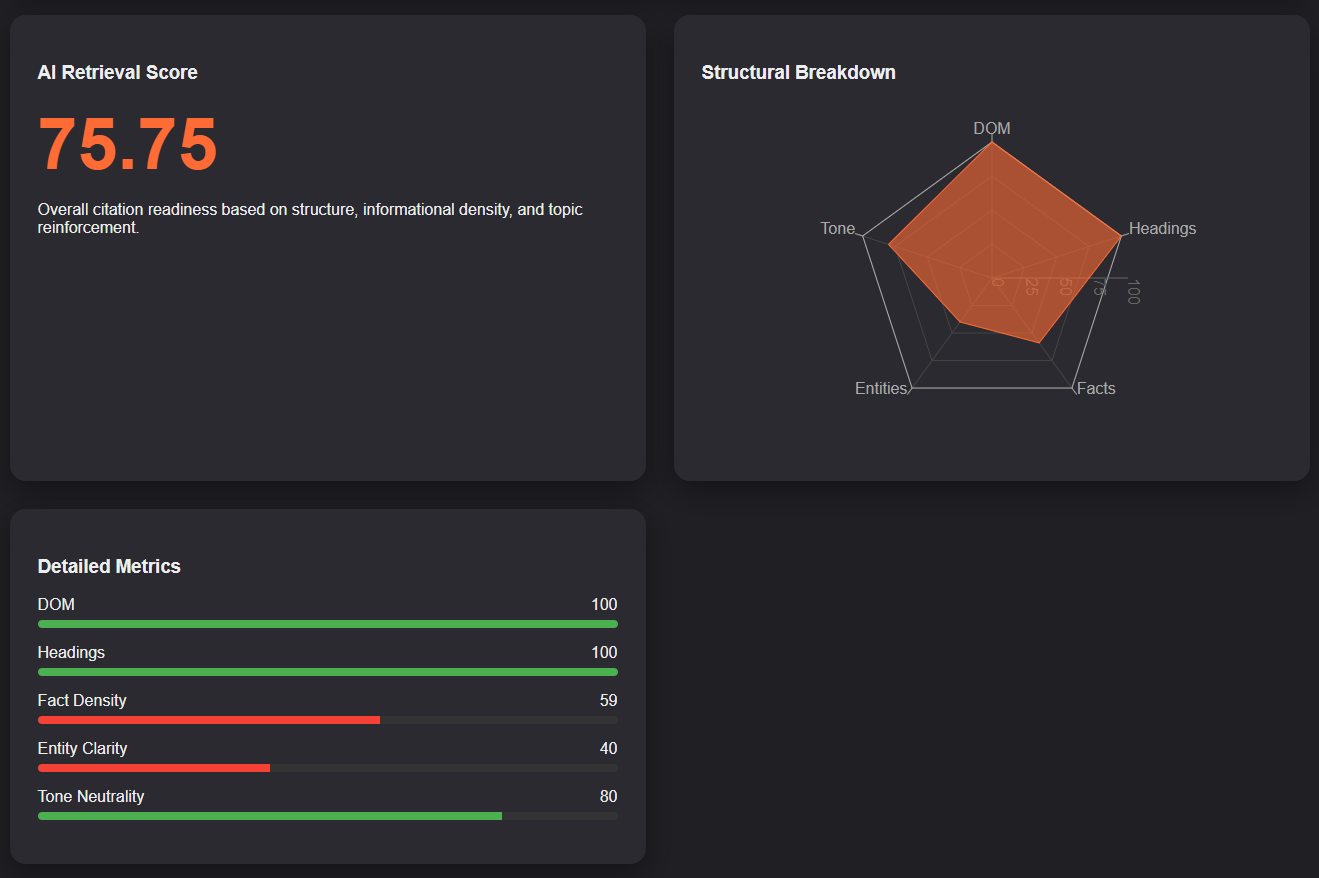
- DOM Extractability Score
- Heading Segmentation Quality
- Section-Level Informational Density
- Lemma-Based Topic Reinforcement
- Entity Clarity Modeling
- Tone Neutrality Assessment
- Deterministic Composite Retrieval Score
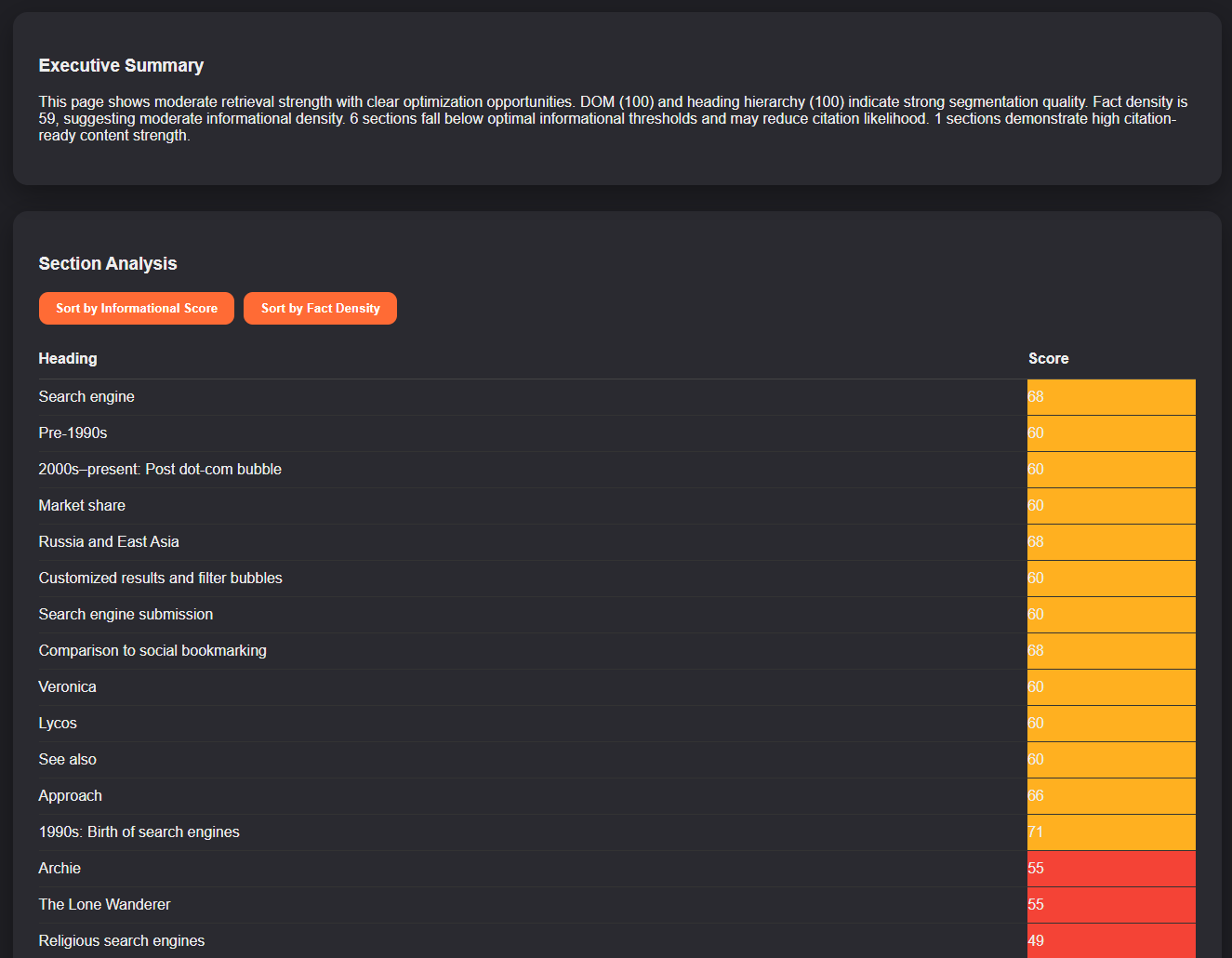
- Section-Level Informational Ranking
- Weak Section Detection
- Competitive Retrieval Comparison
- Winner Detection Logic
Every metric is derived from deterministic backend modeling the frontend only renders computed results.
No synthetic metrics. No heuristic keyword scoring. No client-side logic authority.
Core Capabilities
-
Structural Extractability Modeling
Evaluates DOM clarity, heading hierarchy, segmentation depth, and content-to-container ratios to approximate extractability for retrieval systems.
-
Section-Level Informational Density
Analyzes each content segment independently to determine sentence-level informational richness, noun-verb structural balance, and explanatory density. Computes section-level retrievability scores.
-
Lemma-Based Topic Reinforcement
Uses spaCy lemmatization to normalize topic variants, detect singular/plural consistency, and measure topic reinforcement across segments. Avoids naive string matching and approximates semantic reinforcement modeling.
-
Entity Clarity Modeling
Evaluates named entity distribution, dominant entity reinforcement, and topic coherence strength. Balances entity diversity against topic fragmentation.
-
Deterministic Composite Retrieval Score
Combines weighted metrics including structural segmentation, informational density, topic reinforcement, entity clarity, and tone neutrality. All scoring is backend-authoritative and explainable.
-
Executive Intelligence Layer
Generates automated retrieval readiness summary, weak section detection, strong section identification, and citation risk interpretation. Provides interpretable output not opaque scoring.
-
Competitive Comparison Mode
Allows multi-URL analysis to compute side-by-side retrieval scores, radar comparison, winner detection logic, score differential modeling, and automated comparison summary. Designed for competitive retrieval benchmarking.
-
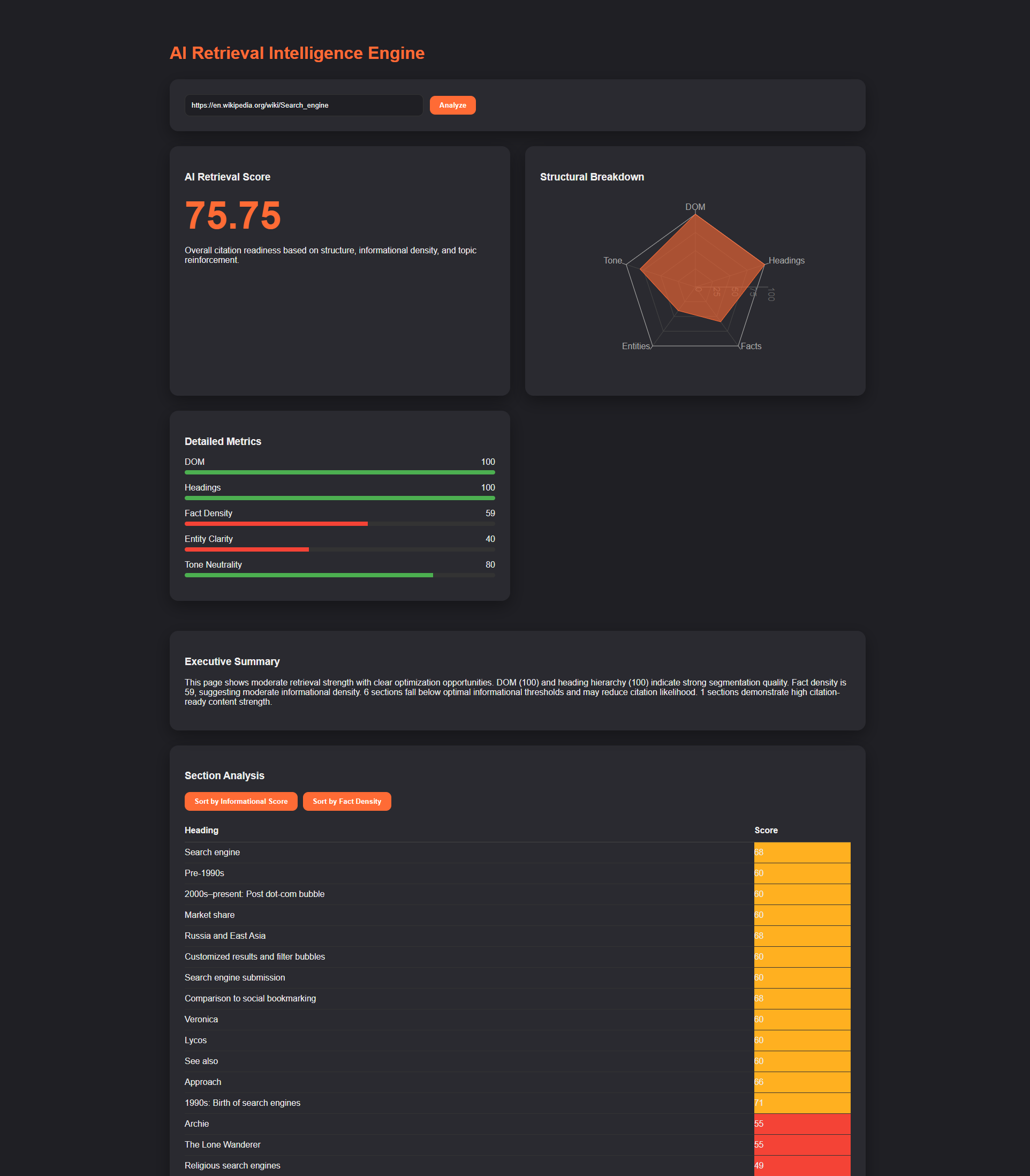
Executive Dashboard Interface
Visualizes animated composite retrieval score, radar structural breakdown, metric bars with severity signaling, section-level retrievability table, collapsible informational drill-down, competitive comparison panel, and winner badge detection.
-
Local-First Architecture
Runs entirely on FastAPI + spaCy + BeautifulSoup backend with React + TypeScript frontend. No external AI APIs, no black-box scoring services, no client-side metric manipulation. All modeling is deterministic and server-side.
The Challenge
AI-native retrieval systems change how content is surfaced.
Pages may rank well but fail to be cited because:
- Sections lack informational density
- Topic reinforcement is inconsistent
- Structure is not extractable
- Content blocks are not self-contained
- Segmentation hierarchy is weak
Traditional SEO reporting cannot detect:
- Which sections are citation-ready
- Which segments are structurally weak
- Where topic drift occurs
- Where entity fragmentation reduces clarity
- Whether content is retrieval-optimized
There was no lightweight, self-hosted system capable of:
- Modeling structural extractability
- Evaluating section-level retrievability
- Applying lemma-based topic reinforcement
- Generating deterministic citation likelihood scores
- Comparing retrieval strength across URLs
The Solution
Built a full-stack retrieval intelligence engine composed of:
Backend:
- FastAPI modeling API
- DOM extractability analyzer
- Heading segmentation modeling
- Section-level informational density engine
- Lemma-based topic reinforcement layer
- Entity clarity scoring
- Tone neutrality modeling
- Deterministic weighted scoring system
- Structured JSON intelligence output
Frontend:
- React dashboard
- TypeScript strict typing
- Dark-mode executive UI
- Animated score transitions
- Radar-based structural visualization
- Section-level retrievability ranking
- Collapsible drill-down interface
- Competitive comparison engine
- Winner detection logic
The system enforces strict backend authority retrieval scores and intelligence outputs cannot be manipulated client-side.
Why It Matters
As AI retrieval systems reshape search behavior, businesses must understand:
- Whether their content is citation-ready
- Which sections are retrievable
- Where structural weaknesses exist
- Where topic reinforcement is insufficient
- How they compare against competitors in retrieval strength
This engine provides a measurable, deterministic framework for evaluating AI retrieval readiness.
It shifts content evaluation from keyword visibility analysis to structural and informational extractability modeling.
Future Expansion
- Optimization recommendation engine
- Persistent audit history
- Retrieval trend tracking
- Configurable scoring weights
- Database-backed audit storage
- Multi-page site analysis
- AI-generated structural improvement suggestions
- SaaS-ready architecture
- Batch URL analysis mode
- Retrieval risk forecasting
Project Positioning Statement
This project represents the architectural foundation for deterministic AI retrieval modeling shifting content analysis from rank-based SEO reporting to structured extractability, informational density, and citation likelihood intelligence infrastructure for the AI-native search era.
Project Details
-
Category SEO Intelligence
-
Architecture Full-Stack
-
Year 2026
Tech Stack
Project Gallery